Introduction
Nature of the topic:
Venture capitalists and other investors have typically relied on their expertise and experience to determine the startups with the greatest return on investment. Data science is already widespread in the financial world, with applications including market trend forecasting, customer segmentation, fraud detection, risk analysis, predictive analytics, and customer sentiment analysis. In this project, data science is leveraged to forecast the potential of success for startups. With our help, startup investors will not require years of experience to know which startups will give high returns on investment. We will follow a multistep approach. First, we will find websites with information about startups and scrape relevant data. Then, we will preprocess this data to prepare it as input to machine learning models. We will use text sources such as news articles to integrate sentiment into our models. After training the models, we will isolate the most relevant factors for startup success. Using that information, we will provide both investors and startup owners with key metrics for success. Our platform is aimed at three groups of people: investors, venture capitalists, and startups. Prospective investors will be able to use our models to determine the best investments. Moreover, startups will gain insights into key factors that should be prioritized for growth.
Why it is important:
Figuring out which companies are worth investing in is a time-consuming and complicated ordeal. Investors are human, and thus make mistakes. Sometimes emotions get in the way, or investors use intuition and trends to guide their decisions. This often leads to poor returns. In his article, “Why It Is Hard To Invest”, Derek Hagen makes the point that our brains are not built for investing. He lists negativity bias, confirmation bias, status quo bias, hindsight bias, and illusion of control as the main reasons people lose in the market. We aim to remedy this with a data-driven approach that cuts out all the human error. We want to provide an unbiased assessment of startups. Furthermore, we want to support entrepreneurship by offering a two-sided solution for investors and startups alike. Entrepreneurial communities produce innovative and exciting new products.
Who is Affected?
Data-driven investing benefits startups and investors simultaneously. Startups gain equity, allowing for greater budgets, and investors have better chances of seeing large returns on their investments. An informed shareholder will hold an executive accountable while funding their business. Additionally, investors incentivize better performance. Shareholders reward innovation and productivity while simultaneously attracting new investors and customers. On a bigger scale, investing in small businesses benefits the economy by creating jobs and circulating money. Increased investing also correlates with consumption. One source claims that “for every dollar of increased stock market wealth, consumer spending rises by 2.8 cents per year” (Sussman). Increased consumer demand encourages businesses to increase supply, expand their business, and create new jobs.
What has been Done, and What Gaps Remain:
Quantitative researchers currently use machine learning techniques to analyze the markets and assess risk. They also develop algorithmic trading software to trade stocks based on daily market predictions. However, market volatility and rapidly shifting market forces can make these models less reliable. Social media influencers who promote or critique products can shift consumer attitudes overnight. Current models lack the data to take these behavior shifts into account. We believe that using sentiment from news articles will help us create more reliable models that are needed in a world that changes every day. Dangl and Salbrechter claim that “Without overnight news, large previous-day returns have marginal predictive power” (Dangl & Salbrechter, 2022). Additionally, there are not many investment platforms that serve both startups and investors. We want to create a model that brings value to both sides of the table.
Conclusion & Summary:
The end goal of this project will be to create versatile models using contemporary approaches. Informed by fundamental but effective data science strategies, we aim to make market success accessible to investors without experience or expertise. We will achieve this through mining and analysis of startup data and sentiment data from articles. This will be impactful to new investors who are interested in entering the market but may be disoriented by barriers to entry such as incomplete or incorrect information from unreliable sources. Our product will be data-driven and unbiased. We want to create something that helps inform and educate others to make wiser decisions with their hard-earned capital. We strive for the lofty goal that our work may be able to improve the investment community in general, or at least act as a stepping stone for market and economic improvement. We are aware of the modern use of machine learning techniques in this field, but we also see how these models are not always reliable. By incorporating novel sources of startup information and sentiment, we strive boldly to discover new insights and make an impact in the field of investment.
Ten Questions for Our Datasets:
- What are the characteristics of startups that have a high annual revenue growth?
- What startups in the past couple of years have had the largest revenue growth?
- Can keywords be used to predict startup performance?
- Do certain news websites better indicate growth? (Forbes, US News, etc.)
- What measurements best predict startup success potential?
- How do startups and data science intersect?
- What are the crucial factors for a successful startup?
- How much does sentiment impact startup success?
- Can we differentiate between sentiment for small businesses versus large businesses?
- Does the industry of a startup affect its success potential?
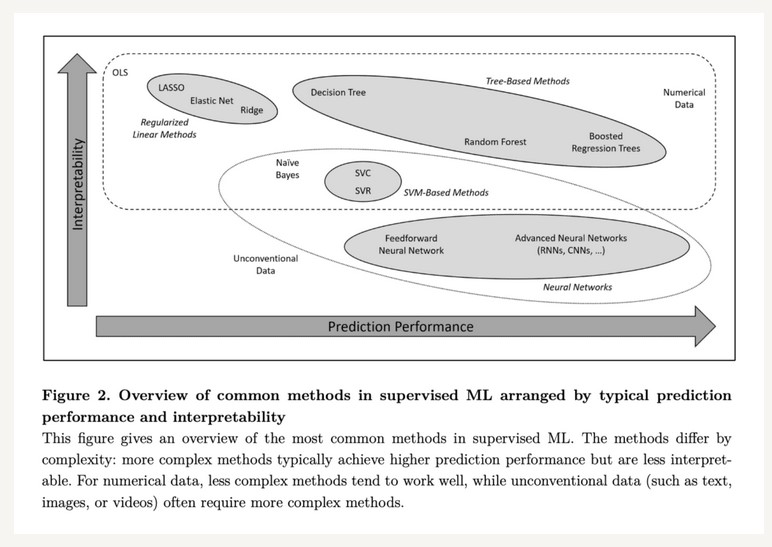 (Quantpedia)
(Quantpedia)
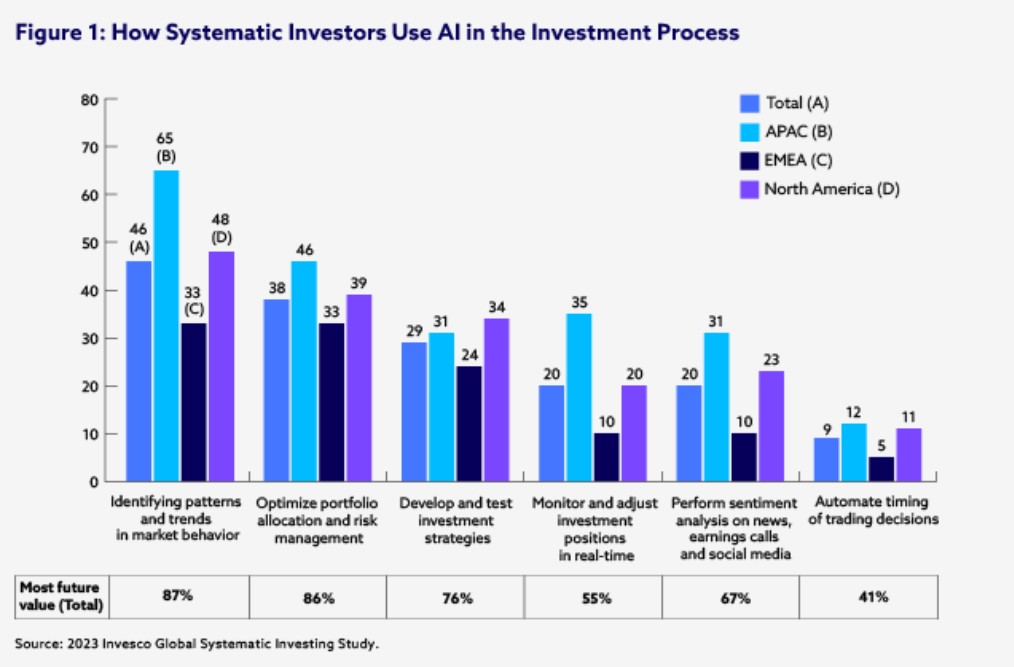 (cfainstitute)
(cfainstitute)
Potential Datasets
- https://www.kaggle.com/datasets/preetviradiya/algorithmic-trading-dataset
- https://www.kaggle.com/datasets/cnic92/200-financial-indicators-of-us-stocks-20142018
- https://www.kaggle.com/datasets/programmerrdai/nvidia-stock-historical-data
- https://www.kaggle.com/datasets/alirezajavid1999/google-stock-2010-2023
- https://www.kaggle.com/datasets/sbhatti/financial-sentiment-analysis
Citations
-
An introduction to machine learning research related to quantitative trading. (n.d.). QuantPedia. https://quantpedia.com/an-introduction-to-machine-learning-research-related-to-quantitative-trading/
-
Briere, Marie and Huynh, Karen and Laudy, Olav and Pouget, Sebastien, What do we Learn from a Machine Understanding News Content? Stock Market Reaction to News (October 19, 2022). Available at SSRN: https://ssrn.com/abstract=4252745 or http://dx.doi.org/10.2139/ssrn.4252745
-
Dangl, Thomas and Salbrechter, Stefan, Overnight Reversal and the Asymmetric Reaction to News (December 20, 2022). Available at SSRN: https://ssrn.com/abstract=4307675 or http://dx.doi.org/10.2139/ssrn.4307675
-
Hagen, D. (2022, December 2). Why it is hard to invest. MeaningfulMoney. https://www.meaningfulmoney.life/post/investing-is-hard
-
Sussman, A. (n.d.). New estimates of the stock market wealth effect. NBER. https://www.nber.org/digest/aug19/new-estimates-stock-market-wealth-effect
-
How Machine Learning is Transforming the Investment Process. (n.d.). CFA Institute. https://www.cfainstitute.org/en/professional-insights-stories/how-machine-learning-is-transforming-the-investment-process